Export
When you're ready to export your tasks, head to the Export page through the dropdown navigation.
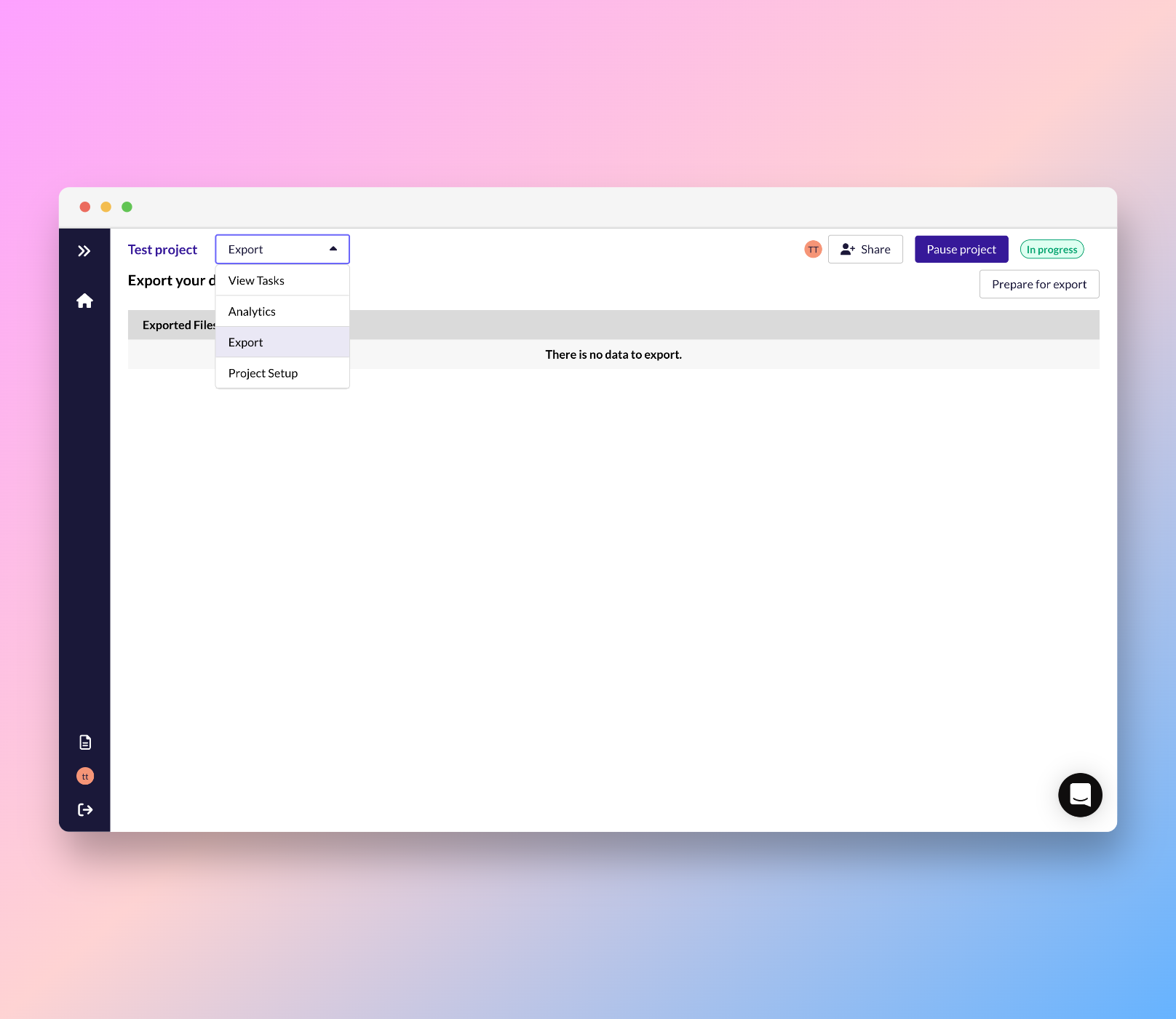
How to export
- Click Prepare for export and select your desired export format.
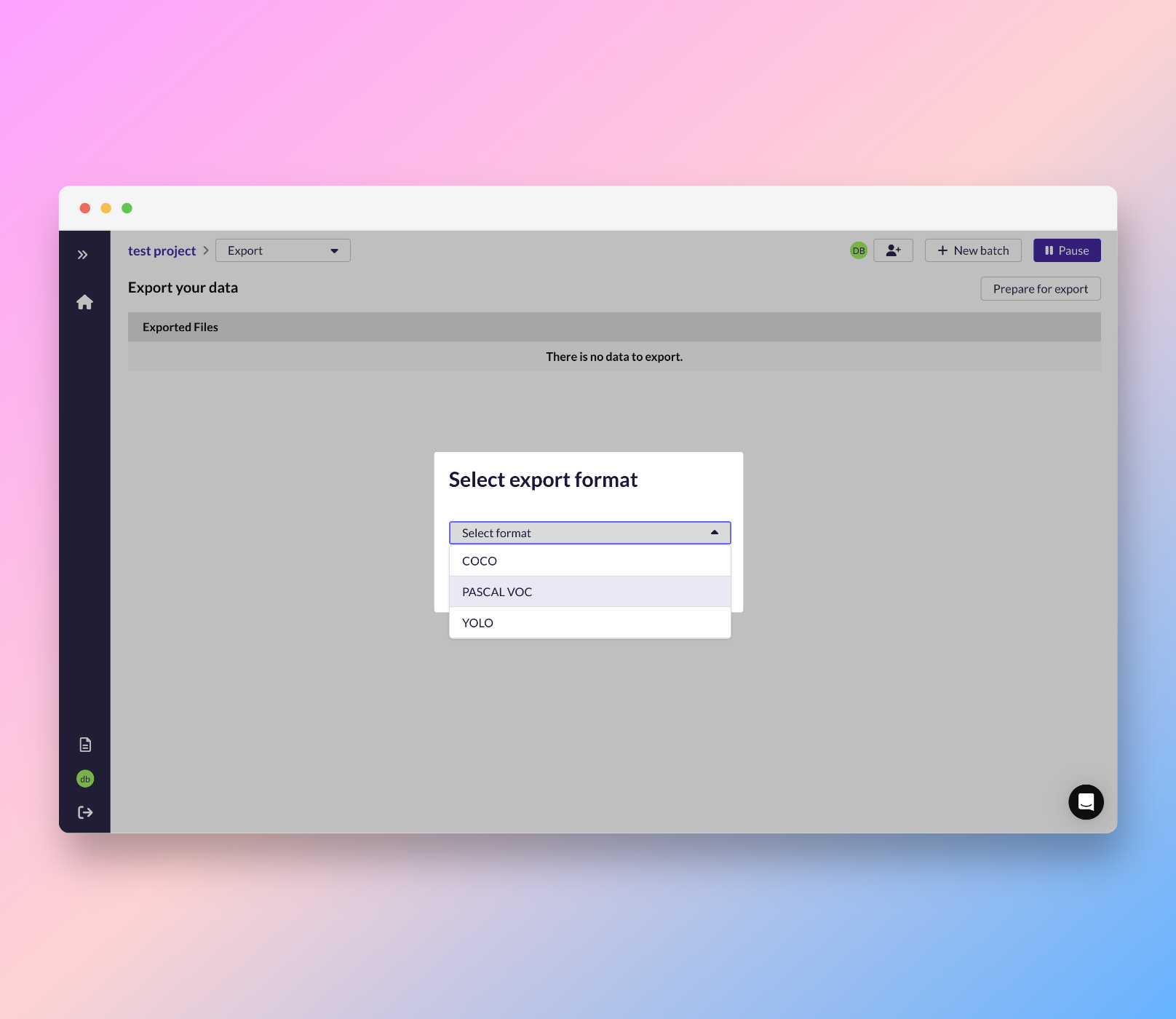
- Click Export.
- Your export will take a few seconds to generate. Click on the download icon to download the export when it's ready.
Annotation Formats
| Annotation Type | Use cases | File Type |
|---|---|---|
| COCO | Supports bounding box and polygon. | JSON |
| Pascal VOC | Supports bounding box and semantic segmentation. | XML |
| YOLO Darknet | Supports bounding box. | TXT |
| SUPA classification | Supports classification. | CSV |
Below contains the expected content format for the formats supported:
COCO
{
"licenses":[
{
"name":"",
"id":0,
"url":""
}
],
"info":{
"contributor":"",
"date_created":"",
"description":"",
"url":"",
"version":"",
"year":""
},
"categories":[
{
"id":1,
"name":"cat",
"supercategory":""
},
{
"id":2,
"name":"dog",
"supercategory":""
}
],
"images":[
{
"id":1,
"width":1280,
"height":720,
"file_name":"animal1.png",
"license":0,
"flickr_url":"",
"coco_url":"",
"date_captured":0
},
{
"id":2,
"width":3266,
"height":1916,
"file_name":"animal2.png",
"license":0,
"flickr_url":"",
"coco_url":"",
"date_captured":0
},
{
"id":3,
"width":2160,
"height":2700,
"file_name":"animal3.jpeg",
"license":0,
"flickr_url":"",
"coco_url":"",
"date_captured":0
}
],
"annotations":[
{
"id":1,
"image_id":1,
"category_id":2,
"segmentation":[
],
"area":181429.7948,
"bbox":[
826.11,
238.86,
447.82,
405.14
],
"iscrowd":0
},
{
"id":2,
"image_id":2,
"category_id":1,
"segmentation":[
],
"area":125742.59949999998,
"bbox":[
1458.95,
318.81,
351.05,
358.19
],
"iscrowd":0
}
]
}
Pascal VOC
Pascal VOC dataset directory should have the following structure:
└─ Dataset/
├── labelmap.txt # or a list of non-Pascal labels in other format
│
└── Annotations/
├── ann1.xml # Pascal VOC format annotation file
├── ann2.xml
└── ...
labelmap.txt defines the custom color map and non-pascal labels
# label:color_rgb:parts:actions
background:0,0,0::
cat:128,0,0::
dog:0,128,0::
Annotations directory contains xml files which provide information about the annotations.
Example xml file, ann1.xml:
<annotation>
<folder></folder>
<filename>ann1.jpg</filename>
<source>
<database>supa</database>
</source>
<size>
<width>500</width>
<height>375</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>cat</name>
<truncated>0</truncated>
<difficult>0</difficult>
<occluded>0</occluded>
<bndbox>
<xmin>179</xmin>
<xmax>231</xmax>
<ymin>85</ymin>
<ymax>144</ymax>
</bndbox>
</object>
<object>
<name>helmet</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<occluded>0</occluded>
<bndbox>
<xmin>112</xmin>
<xmax>135</xmax>
<ymin>145</ymin>
<ymax>175</ymax>
</bndbox>
</object>
</annotation>
YOLO Darknet TXT
YOLO dataset directory should have the following structure:
└─ project_id/
│
├── obj.names # file with list of classes
├── obj.data # file with dataset information
├── train.txt # list of image paths in train subset
│
└── obj_train_data/ # directory with annotations for train subset
├── image1.txt # list of labeled bounding boxes for image1
├── image2.txt
└── ...
obj.names contains a list of classes. The line number for the class is the same as its index:
label1 # label1 has index 0
label2 # label2 has index 1
label3 # label2 has index 2
...
obj.data has the following content:
classes = 3 # number of classes
train = data/train.txt # path to train.txt
names = data/obj.names # path to obj.names
backup = backup/
obj_train_data/ contains text files which provide information about the labeled bounding boxes. Each .txt file corresponds to one image with a single line for each bounding box.
The format of each row is label_index, center_x, center_y, width, height, where coordinates are normalised from zero to one.
- The index for labels can be found in the file obj.names.
- The x_center and y_center are centers of rectangle (not top-left corner).
Example txt file, image1.txt:
0 0.617 0.3594420600858369 0.114 0.17381974248927037
2 0.094 0.38626609442060084 0.156 0.23605150214592274
Creating YOLOV5 files from YOLO Darknet
YOLOv5 has two main files:
.txt filecontaining annotationsdata.yamlfile containing configuration values for models to locate images and map class names to class index
Steps to convert YOLO Darknet to YOLOv5:
- The .txt files for YOLOv5 and YOLO Darknet are identical, so no actions are required.
- Create a text file using the format in the example below and then add a
.yamlextension.
- nc: Number of classes. Can be found in
obj.datafile. - names: Array with the classes. Sequence of the class elements can be found in
obj.names
train: ../train/images
val: ../valid/images
nc: 3
names: ['head', 'helmet', 'person']
Need a different export format?
Email us at [email protected] or drop us a message via Intercom.
Updated over 1 year ago